

Merhaba, Python kullanarak veri madenciliği (web scraping) yapmak günümüzün popüler konularından bir tanesi. Hem gelişmiş kütüphaneler, hem de Python söz diziminin diğer dillere göre nispeten daha kolay olmasından dolayı Python bu işte çok yetenekli. İnternetteki verinin değeri ise paha biçilemez seviyeye gelmiş durumda. Böylesine bir madenin en hızlı nasıl kazılacağını bu yazımda sizlere bahsettim. Keyifli okumalar dilerim.
HTTP istemcileri (HTTP clients)
Python’da birçok HTTP istemcisi bulunuyor. Bunlardan bazıları;
- Requests (en yaygın kullanılan)
- Urllib
- PycURL
- Faster-than-request (en hızlısı fakat gelişmesi lazım)
Aralarında en kararlı çalışan requests modülü olduğu için bu yazıda onu kullanacağız.
Çalıştırma yöntemleri
Aslında bize zaman kazandıracak olay burada başlıyor. Kodumuzu çalıştıracağımız yöntem türüne göre veri hızı inanılmaz boyutta artıyor. Dilerseniz yöntemlerden ve detaylarından bahsedelim. En hızlıdan, en yavaşa sıralayacak olursak.
- aiohttp ile asenkron çalıştırmak.
- concurrent.futures ile paralel çalıştırmak.
- requests.session ile oturum oluşturmak.
- requests.get kullanmak (en yaygın kullanılanı bu).
Şimdi bu yöntemleri tek tek deneyerek sonuçlara göz atalım. Bunun için aşağıdaki kodu kullanabiliriz.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import requests
import aiohttp
import asyncio
from requests_futures import sessions as ses
import contextlib
import time
URL = 'http://httpbin.org/gzip'
COUNT = 50
@contextlib.contextmanager
def calc_execution_time(method):
start_time = time.time()
yield
print("`%s' yönteminde geçen zaman: %.2fs" % (method, time.time() - start_time))
with calc_execution_time("requests"):
for i in range(COUNT):
requests.get(URL)
sessions = requests.Session()
with calc_execution_time("session"):
for i in range(COUNT):
sessions.get(URL)
session = ses.FuturesSession(max_workers=10)
with calc_execution_time("concurrent.futures"):
futures = [session.get(URL)
for i in range(COUNT)]
for f in futures:
f.result()
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
await response.read()
loop = asyncio.get_event_loop()
with calc_execution_time("aiohttp"):
loop.run_until_complete(
asyncio.gather(*[get(URL)
for i in range(COUNT)]))
Çıktı olarak elde ettiğimiz sonuç ise muazzam!
1
2
3
4
requests yönteminde geçen zaman: 15.85s
session yönteminde geçen zaman: 9.12s
concurrent.futures yönteminde geçen zaman: 1.08s
aiohttp yönteminde geçen zaman: 0.58s
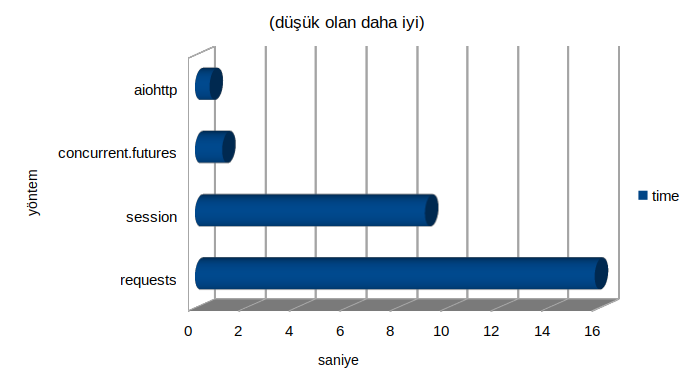
Kod çıktısı ve grafik bize gösteriyor ki asenkron yöntem, geleneksel yöntemden 27 kat daha hızlı.
- Ayrıca söylemek gerekirse, scriptinizi kontrolsüz bir şekilde asenkron veya paralel çalıştırırsanız büyük ihtimal hedef websitesinin güvenlik duvarı tarafından engelleneceksiniz. Fazla abartmamakta fayda var.
Son Sözler
Kısa ve öz bir yazı oldu fakat teknik açıdan birçok geliştiriciye yön göstereceğine inanıyorum. Maalesef ki veri madenciliği konusunda yeterli Türkçe kaynak yok, olanlar da bilgi açısından tatmin etmeyecek seviyede. Eğer bu alanda iş yapmak istiyorsanız size tavsiyem Github üzerinden insanların kodlarını okumanız olacaktır.
Herkese kolay gelsin.
Kaynakça:
- https://docs.aiohttp.org/en/stable/client_quickstart.html
- https://docs.python.org/3/library/concurrent.futures.html
- https://julien.danjou.info/python-and-fast-http-clients/